NLP classification: Determine Hackernews post category with Python

The purpose of the small project is to determine in which category (computer science, biology, etc) a HackerNews post belongs to. This post is the first step of a bigger project. The code is available on Github, so please, don't hesitate to criticize it or do some pull request. :)
0. Pipeline
TLDR : To summarize, I train my model with a dataset created from scratch with Arxiv.org, then I do predictions with articles from HackerNews.
The pipeline used on this project is the following :
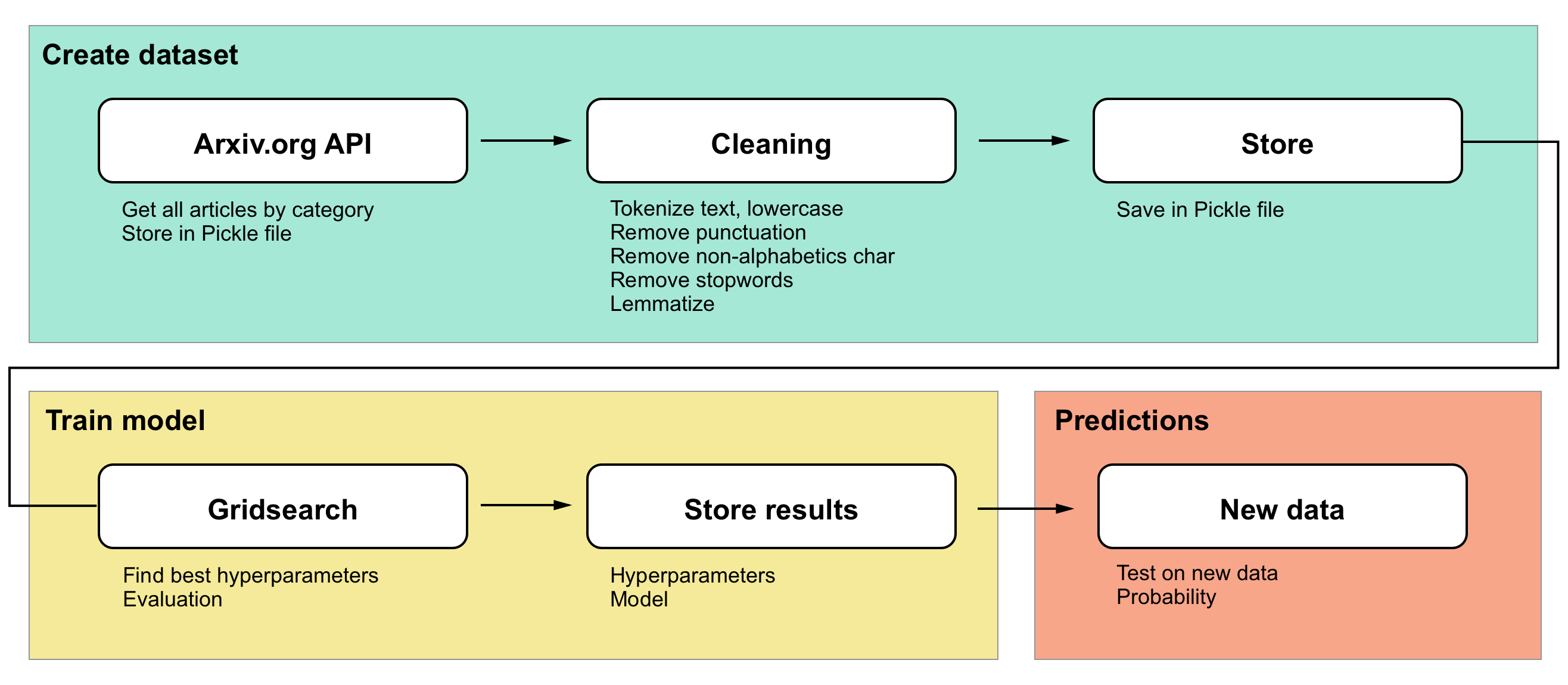
1. Create dataset
To classify text, it's necessary to have a large dataset. I found one easy way to do it using arXiv.org's API. There are many other sources, but I found that one useful because it seems to have the same categories as HackerNews.
ArXiv.org API
ArXiv.org store papers about physics, Mathematics, Computer Science, Quantitative Biology, etc. The first step is to find all categories on the website. I found the pattern used on ArXiv.org to categorize each paper:
| Category | Regex |
|---|---|
| Computer science | cs* |
| Physics | astro-ph*, cond-mat*, gr-qc*, hep-ex* |
| hep-lat*, hep-ph*, hep-th*, math-ph* | |
| nlin*, nucl-ex*, nucl-th*, physics* | |
| quant-ph*, quant-ph* | |
| Mathematics | math* |
| Quantitative Biology | q-bio* |
| Quantitative Finance | q-fin* |
| Statistics | stat* |
| Economics | econ* |
| Electrical Engineering and Systems Science | eess* |
Those patterns will help to extract the data with Arxiv API.
What I need from ArXiv.org
As you can see on the following picture, not only the title can give information about the topic, but also the summary. The more data, the better the predictions.

Download and archive raw information
I use the Python's library Request to call the API and XML to parse each entry. The API gives precious information such as : Title, summary, primary category, authors, link, etc.
The API is easy to use, the parameter cat take the category pattern showed earlier. For example:
http://export.arxiv.org/api/query?search_query=cat:cs*&start=0&max_results=1000
The first script gets the information and store them in an array. A query is executed in order to get all the articles from a specific category.
# For each item
for r in xml_root.findall('{http://www.w3.org/2005/Atom}entry'):
# Get ID, URL, Title, Summary and Primary category
id = r.find('{http://www.w3.org/2005/Atom}id').text.replace('http://arxiv.org/abs/', '')
url = r.find('{http://www.w3.org/2005/Atom}id').text
title = r.find('{http://www.w3.org/2005/Atom}title').text
summary = r.find('{http://www.w3.org/2005/Atom}summary').text.replace('\n', ' ')
cat_sub = r.find('{http://arxiv.org/schemas/atom}primary_category').attrib['term']
An article contains the following information :
- id : reference on arxiv.org
- title
- cat_main : primary category (ex: computer science)
- cat_sub : secondary category (ex: cs / image processing)
- url
- sum : summary
- input : summary + title
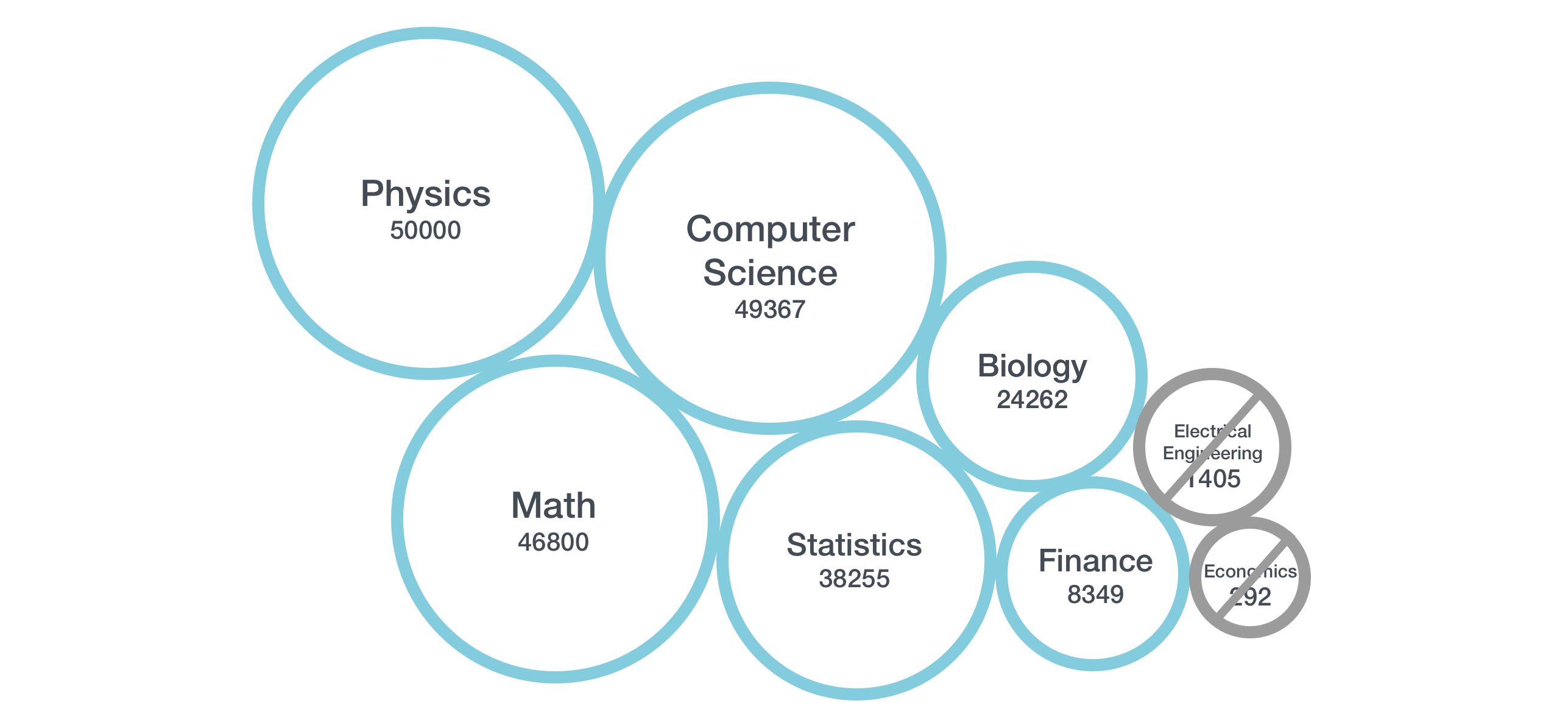
At the end, raw information are stored in a pickle file. About 218730 entries! Number of articles per category :
Physics : 50000
Computer Science : 49367
Mathematics : 46800
Statistics : 38255
Quantitative Biology : 24262
Quantitative Finance : 8349
Electrical Engineering and Systems Science : 1405
Economics : 292
Total data: 218730
The code is available here
2. Clean dataset
If you already did some data mining, raw data contains a lot of unnecessary information, such as stop words, etc. A clean dataset will gives better results. Don't be afraid to spend more time on it. For this project I used NLTK library.
The cleaning method is the following :
def clean_text(text):
# split into words
tokens = word_tokenize(text)
# convert to lower case
tokens = [w.lower() for w in tokens]
# remove punctuation from each word
table = str.maketrans('', '', string.punctuation)
stripped = [w.translate(table) for w in tokens]
# remove remaining tokens that are not alphabetic
words = [word for word in stripped if word.isalpha()]
# filter out stop words
stop_words = set(stopwords.words('english'))
words = [w for w in words if not w in stop_words]
stemmed = [wordnet.lemmatize(word) for word in words]
return ' '.join(stemmed) # Return a string
clean_text() receives the raw text, and several cleaning methods are applied to it :
- Tokenize text : Split text based on "space" character
- Lower text : Lowercase
- Remove punctuation
- Remove non-alphabetics char
- Remove stopwords : Here in english only
- Lemmatize : Find the inflected forms of a word. There is different methods such as
PorterStemmer,SnowballStemmer,WordNetLemmatizer, etc. For this article I usedWordNetLemmatizer.
This method clean the title and summary. At the end, I store the final dataset in a pickle file.
The dataset is available here.
This second script is available here
3. Create the model
Sklearn library provides a grid search method in order to get the best hyperparameters of a specific model. I wanted a model which provides a probabilistic prediction based on the category. The output category for a text will be something like : 80% Computer science, 10% Biology, etc.
For example, when a probability of less than 60% I can say that the output category is not guaranteed, because not sufficiently accurate.
As you can see, on the following picture, the number of articles per category is different depending on the category. Because of the relatively low number of articles for the categories Electrical Engineering and Economics, I decided to remove them from the training set. Preserving them will return bad accuracy due to the number of entries.
Having unbalanced class can cause a high bias on prediction. With the lowest category (Finance, which has 8349 entries), we need to reduce the number of entries for the other categories. All the categories will have 8349 entries in order to have balanced classes. See image :
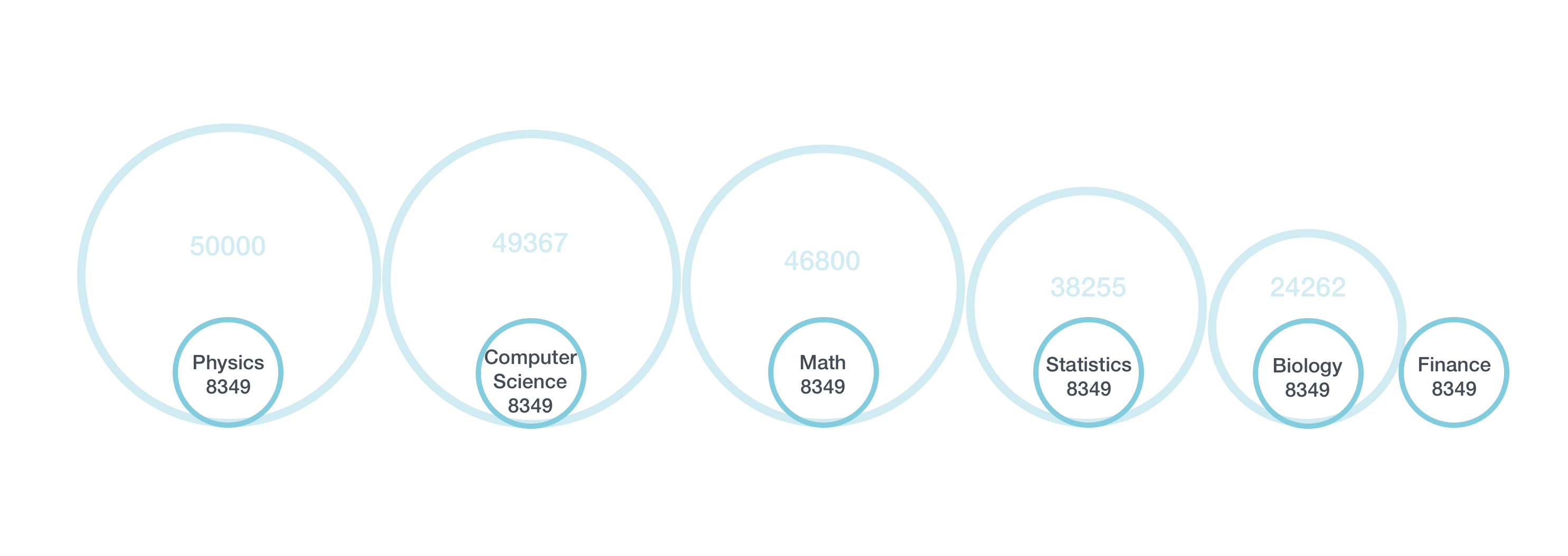
The dataset is now ready to be processed by the pipeline!
Gridsearch
Pipeline :
pipeline = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('kbest', SelectKBest()),
("SGD", SGDClassifier(loss='modified_huber')),
])
CountVectorizer : Convert a collection of text documents to a matrix of token counts.
TfidfTransformer : Transform a count matrix to a normalized tf or tf-idf representation.
SelectKBest : Select features according to the k highest scores. The purpose is to reduce the dimension of the matrix.
SGDClassifier : Our model. A simple SGD Classifier.
This is the list of the hyperparameters. It's mandatory to use only "log" and "modified_huber" loss parameters to get the prediction probability.
parameters = {
'vect__max_df': np.arange(0.7, 1, 0.05),
'vect__ngram_range': ((1, 1), (1, 2)), # unigrams or bigrams
'tfidf__use_idf': (True, False),
'tfidf__norm': ('l1', 'l2'),
'kbest__k': np.arange(3000, 15000, 500),
'kbest__score_func': (chi2, f_classif, f_regression),
'SGD__loss': ('log', 'modified_huber'), # only those two for probability estimation
'SGD__penalty': ['l2'],
'SGD__alpha': [0.001, 0.0001, 0.00001, 0.000001, 0.0000001, 0.00000001]
}
The python file is available here
Results
Now it's time to create the test and training set and train our model with the hyperparameters found with the gridsearch.
Classification report
After training our model, the average precision is about ~0.88, which is enough to predict the category of an article. Indeed, to improve our model we can try to find better hyperparameters, but it will not increase more than 0.05. A better solution is to analyse the text again and make better data mining choices before to give the text to the model.
It's always better to spend more time on the dataset than trying to improve a model by changing its hyperparameters.
precision recall f1-score support
Computer Science 0.82 0.85 0.84 2782
Mathematics 0.91 0.93 0.92 2794
Physics 0.91 0.89 0.90 2691
Quantitative Biology 0.86 0.88 0.87 2666
Quantitative Finance 0.93 0.92 0.93 2792
Statistics 0.82 0.79 0.80 2709
-------------------------------------------------------------
avg / total 0.88 0.88 0.88 16434
4. Predictions
Let's get two articles from Hacker News and predict theirs categories :
The first article comes from www.mac4n6.com. It's a post about APFS on macOS.
Result : [[ 0.79656177, 0., 0.13604312, 0.02635796, 0.04103715, 0.]]
Predict : Computer Science with an accuracy of ~0.79. Which is higher than the other categories.
The second article comes from www.smithsonianmag.com. The article talks about giraffes, so it would be categorized as Biology.
Result : [[ 0.13082693, 0.10773755, 0., 0.76143552, 0., 0.]]
Predict : Quantitative Biology with an accuracy of ~0.76.
Futur work
The predictions are quite good, I will probably do another article about an application linked to the HackerNews API in order to predict each new article.
Another improvement would be to predict each subcategories. For example, for Computer Science, the subcategories are : Artificial Intelligence; Computation and Language; Computational Complexity, etc. Subcategories are already on the dataset that I created.
If you are interested in this article, please share it, and if you find another better solution, with a better accuracy, please write a comment. :)
Image credit : Annie Spratt
Member discussion