Language learning with Whisper

OpenAI, a Silicon Valley AI firm founded by Elon Musk, released an open-source automatic speech recognition (ASR) system called Whisper that can transcribe numerous languages. Improved robustness to accents, background noise, and technical language is due to the fact that Whisper was trained on 680'000 hours of multilingual data.
In this blog post, I will use Whisper as a tool to help you practice your listening skills for language learning. The following sections will show you how to install Whisper and use it to transcribe audio files.
What is Automatic Speech Recognition (ASR)?
Automatic speech recognition (ASR) is the process of converting speech into text automatically.
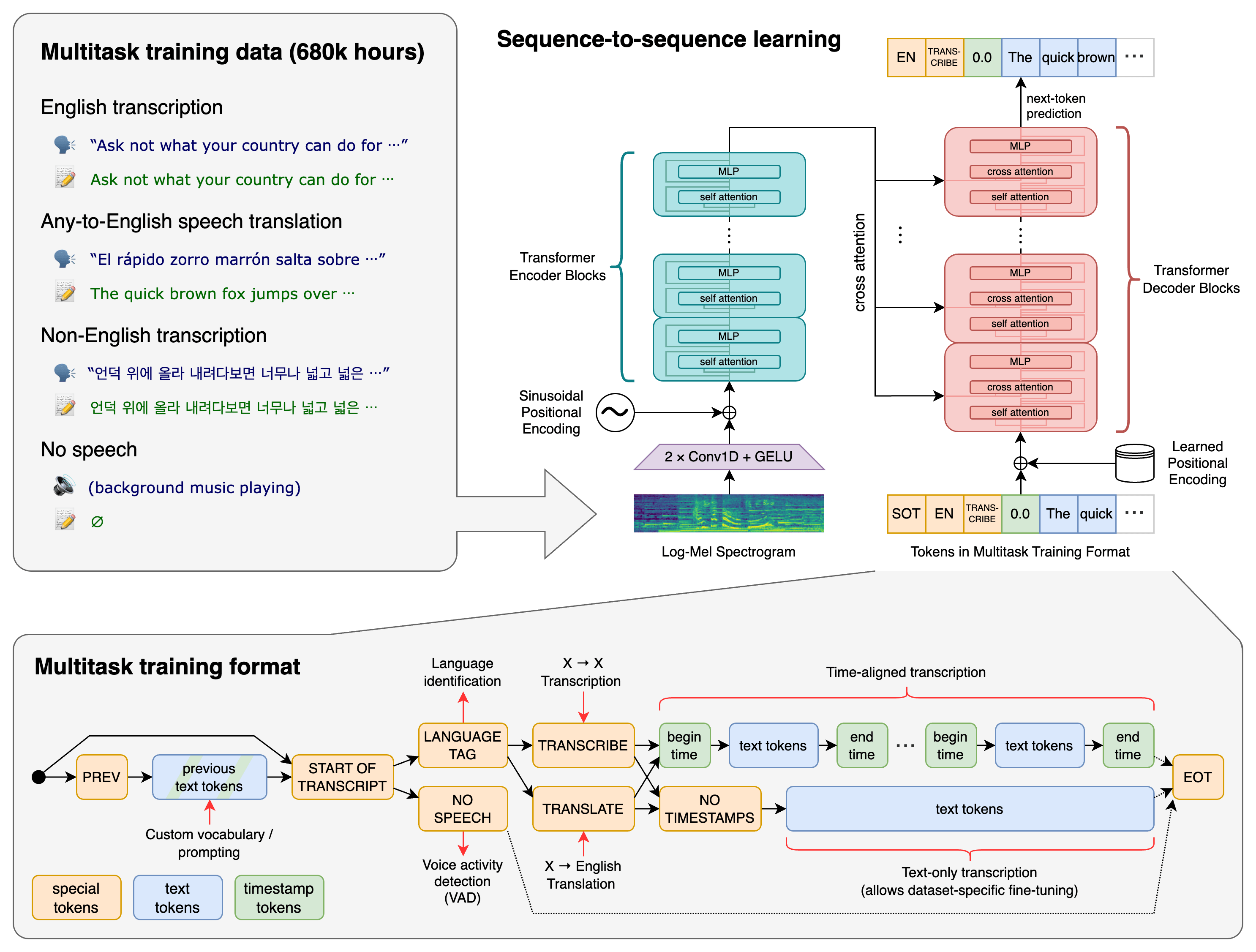
ASR systems are composed of two main components: an acoustic model and a language model. The acoustic model is trained on audio data and primarily consists of a hidden Markov model (HMM). The language model is trained on text data and can be either a statistical language model (SLM) or a neural network language model (NNLM).
Whisper' models are trained on 680,000 hours of audio, and the corresponding transcripts are gathered from the internet. Roughly 65% of the data (or 438,000 hours) is in English, with matching English transcripts (or roughly 18%), while 17% (or 117,000 hours) is in non-English and accompanied by a translated text. This non-English material comprises 98 different languages.
Transformer model: Encoder-decoder
Installation
Dependencies
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpegpip3 install setuptools-rustClone project
pip3 install git+https://github.com/openai/whisper.git How about language learning?
One of the best ways to learn a language is by listening to audio recordings of native speakers. This will help you to hear the correct pronunciation and also to learn new words and expressions.
Additionally, audio recordings can help you to better understand the flow of the language and the rhythm of the language. This can be especially helpful when you are starting out with a new language and are still working on your basic skills.
How do I use it?
I started to learn Mandarin ~3 years ago, and I've been struggling with listening for quite a long time. FYI There are four tones in Mandarin, and a change in tone can completely alter the meaning of a word.
Basically, what I'm doing to practice listening by myself, is to watch kids TV shows. Especially because some of them are quite "easy" to understand, and it's a nice way to learn new words.
1. Find a video
Let's take this video as our example. The videos have subtitles, and we will use those subtitles to compare the model' accuracy.
2.Convert the video to mp3
Well, there's some websites to convert youtube video to mp3...
3.Split the audio
Being able to replay a though part of the audio greatly helps to make it easier to understand.
I'm splitting the audio in several chunks based on the silent parts:
from pydub import AudioSegment
from pydub.silence import split_on_silence
if __name__ == '__main__':
# get audio file
sound_file = AudioSegment.from_mp3("audio.mp3")
# split in chunks
audio_chunks = split_on_silence(sound_file, min_silence_len=200, silence_thresh=-40)
for i, chunk in enumerate(audio_chunks):
out_file = "chunk{0}.mp3".format(i)
# export audio
chunk.export(out_file, format="mp3")4.Run the model on a audio chunk
# load model
model = whisper.load_model("medium")
# let's get the text from the audio, I explicitly say the language is mandarin (zh)
result = model.transcribe("chunk2.mp3", language='zh')
print(result["text"])5. Complete code
import whisper
from pydub import AudioSegment
from pydub.silence import split_on_silence
if __name__ == '__main__':
# load model
model = whisper.load_model("small")
# get audio file
sound_file = AudioSegment.from_mp3("audio.mp3")
# split in chunks
audio_chunks = split_on_silence(sound_file, min_silence_len=200, silence_thresh=-40)
for i, chunk in enumerate(audio_chunks):
out_file = "chunk{0}.mp3".format(i)
print("exporting", out_file)
# export audio
chunk.export(out_file, format="mp3")
# let's get the text from the audio
result = model.transcribe(out_file, language='zh')
print(result["text"])Accuracy
Let's compare a few audio
| Original text | base model | small model | medium model | large model |
|---|---|---|---|---|
| 沒問題啦 | ✓沒問題啦 (1.27s) | ✓沒問題啦(3.63s) | ✓沒問題啦(10.22s) | ✓沒問題啦(16.63s) |
| 馬鈴薯要四顆,小黃瓜要兩條哦 | 馬鈴手要四顆,小黃瓜要兩條哦 (2.97s) | 馬鈴薯鴨四顆,小黃瓜要兩條哦!(8.89s) | ✓馬鈴薯要四顆,小黃瓜要兩條哦(24.51s) | ✓馬鈴薯要四顆,小黃瓜要兩條哦(41.00s) |
| 那我去買東西了路上小心哦 | ✓那我去買東西了路上小心哦 (5.86s) | ✓那我去買東西了路上小心哦!(17.25s) | 那我去買東西了路上小心喔(48.69s) | ✓那我去買東西了路上小心哦(81.89s) |
Obviously, the accuracy improves depending on the model used. For a time/precision ratio, I think the medium model is enough.
Conclusion
That's it! This short blog post demonstrate how to easily install and use Whisper, and how remarquable the accuracy is. How about you? Tell me how you will use Whisper if you also use it for language learning :)
Sources
Photo by Compare Fibre on Unsplash
 openai
openai


Member discussion